
AI is governable. If you can see it.
Most security programs treat AI as a vendor risk: a checkbox under third-party. The actual surface is wider — SDK integrations, fine-tunes, prompt-tuned customizations, agent frameworks. PolicyCortex discovers all of it, maps adversarial risk to MITRE ATLAS, and uses cost anomalies as the early signal for activity that hasn't breached yet.
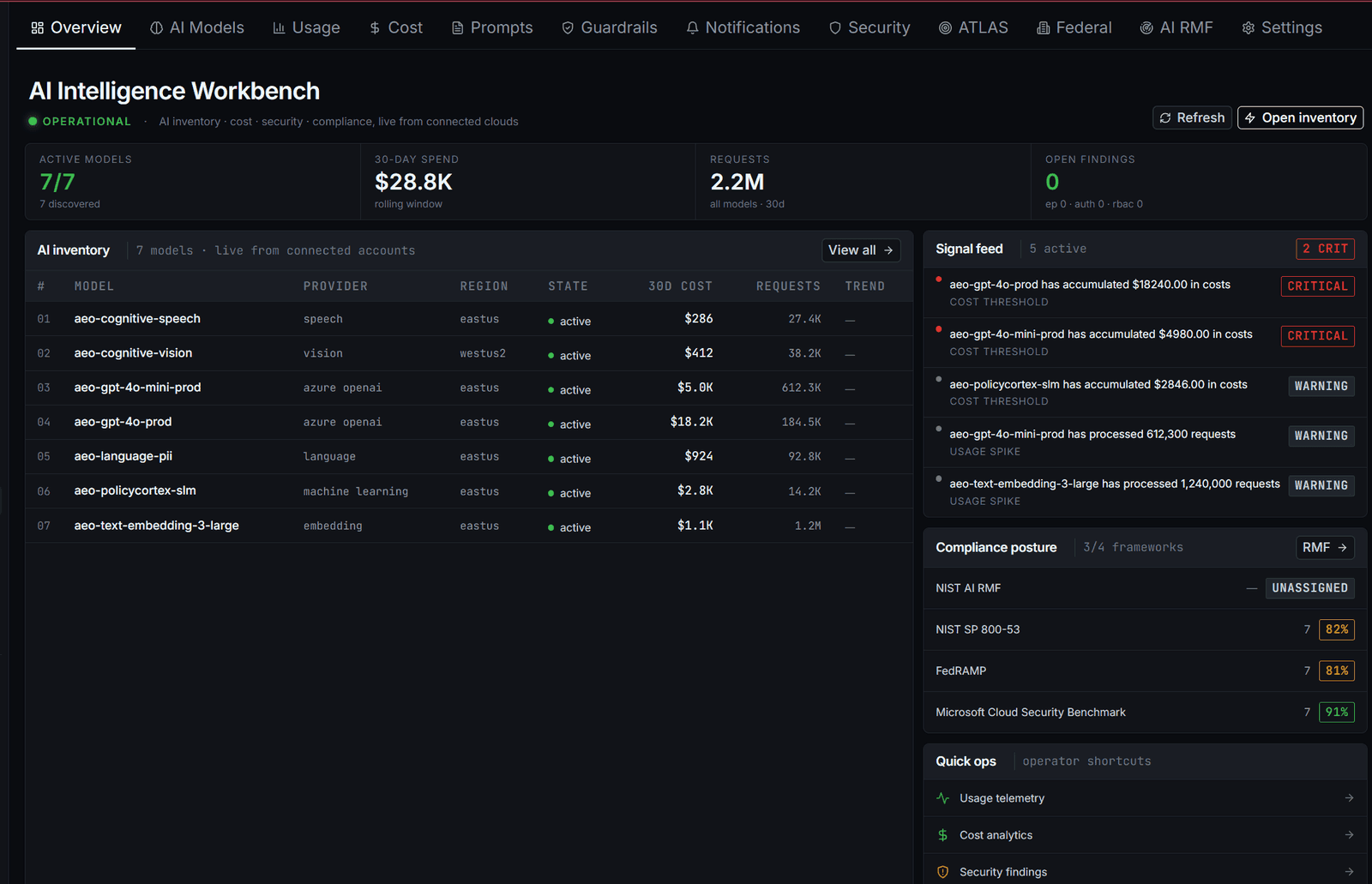
You have 3–10× more AI than security knows about.
The CISO spreadsheet lists the managed endpoints procurement bought: Azure OpenAI, Bedrock, Vertex. The actual surface includes every SDK-integrated call from product teams, every fine-tuned adapter sitting in a dev workspace, every prompt-tuned customization that calls out to a third-party API, every agent framework with tools mounted, every model pulled from Hugging Face into a container.
PolicyCortex enumerates by tracing API egress + cloud control-plane + workspace inventory. Discovery runs on the same schedule as a CSPM scan — every model gets an owner, a risk class, and an ATLAS-relevant exposure profile within the first 24 hours.
Adversarial AI techniques get the same SOC treatment as ATT&CK.
MITRE ATLAS is the AI counterpart to ATT&CK — named tactics, named techniques, structured for SOC tooling. PolicyCortex maps every model + every signal to ATLAS so adversarial activity surfaces in the same queue, with the same playbooks, as network and identity findings.
- AML.T0048ML Model Access
Prompt Injection
Adversarial input crafted to override system instructions, exfiltrate context, or escalate privilege. PolicyCortex flags on pattern + downstream behavior — not pre-defined block lists.
- AML.T0051Defense Evasion
LLM Jailbreak
Multi-turn conversational technique to bypass safety filters. Detected by conversation-shape analysis + token-distribution shifts vs the model's baseline.
- AML.T0023ML Model Access
Model Evasion
Inputs perturbed to cause misclassification. Vision + tabular classifiers; OCR-based exfiltration paths. PolicyCortex monitors decision-boundary stability over time.
- AML.T0024Resource Dev
Training Data Poisoning
Adversary injects samples into training corpus to degrade or backdoor the model. Detected at the data-supply chain: hashes drift, provenance gaps, scope creep.
- AML.T0017Exfiltration
Model Theft
Query-volume attack that reconstructs the model from outputs. Caught by anomalous query patterns + provider-side rate signals.
- AML.T0040Impact
ML Model Inference DoS
High-cost queries (long-context, image gen) flood inference budget. PolicyCortex couples to FinOps anomaly detection — cost spike opens a security investigation, not a billing ticket.
A 4× token-spend spike is a security event.
Adversarial activity against managed AI shows up in token usage before it shows up anywhere else. Model-theft via repeated boundary-probing queries. DoS via long-context floods. Exfiltration through large-context calls that paginate sensitive data.
PolicyCortex couples the same anomaly engine FinOps uses to the security investigation pipeline. Cost anomaly without business justification opens an ATLAS-mapped finding. Same workflow as a network alert. Same MTTR target.
- 01ANOMALY
Token spend exceeds 3σ for model class + business unit.
- 02CLASSIFY
FinOps engine routes: business reason known → cost ticket. Unknown → security.
- 03ATLAS MAP
Pattern matched to adversarial technique (T0040, T0017, T0023…).
- 04INVESTIGATE
SOC playbook opens. Same surface as a network finding. Same dashboard.
- 05REMEDIATE
Throttle, isolate, or revoke. Runs through autonomous remediation.
Every model action emits evidence aligned to GOVERN · MAP · MEASURE · MANAGE. Same evidence substrate as the governance module — hashed, OSCAL-portable, assessor-ingestible.
What is MITRE ATLAS?
MITRE ATLAS (Adversarial Threat Landscape for AI Systems) is a knowledge base of adversary tactics and techniques targeting AI/ML — the AI counterpart to MITRE ATT&CK. Mapping AI risk to ATLAS lets the same SOC playbooks that cover network and identity also cover model surface.
What does 'shadow AI' actually mean here?
Models procured by individual teams that security never inventoried: SDK integrations, agent frameworks, fine-tunes pushed to dev workspaces, prompt-tuned customizations of managed endpoints. In our sample tenants, 3–10× more model entry points exist than the CISO's tracking spreadsheet shows.
Why treat cost as a security signal?
Adversarial activity against managed AI almost always shows up in token usage first — DoS-style query floods, model-theft reconstruction queries, exfiltration via large-context calls. FinOps anomalies that don't have a business reason open a security investigation, not a finance ticket. Same signal, two readers.
How does this satisfy EO 14110 / NIST AI RMF?
PolicyCortex generates evidence aligned to all four AI RMF functions (GOVERN, MAP, MEASURE, MANAGE) continuously. Each model's risk classification, owner, and adversarial-technique exposure is captured and OSCAL-portable. The AI RMF "profile" assessors expect is a generated artifact.
Find the AI your spreadsheet doesn't know about.
30 days, $15K flat. Connect cloud + AI endpoints, baseline ATLAS posture, walk away with an EO 14110-aligned governance report.